
AI 理论:Tool 介绍
AI 理论:Tool 介绍
salt-fish关于本笔记
本笔记用于介绍 Tool(工具)在 Agent 中的作用、Tool 的四要素定义(函数本体、名称、描述、参数定义),以及不同风险等级的工具分类。
目录
一、Agent + Tool:两个角色怎么配合干活
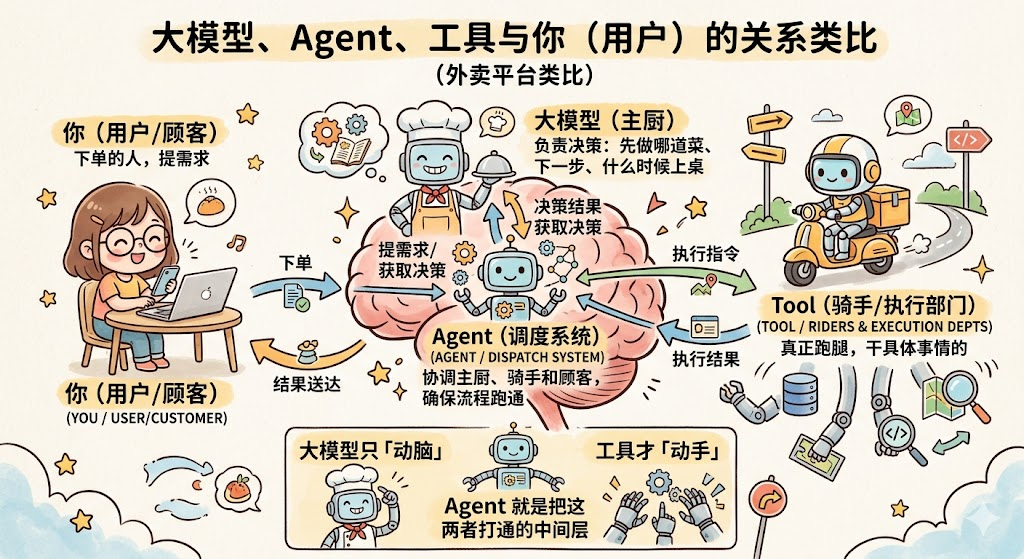
在聊 Tool 之前,先把另一个容易混淆的概念说清楚: Agent 。
很多同学以为「Agent 就是更厉害的大模型」。这个理解偏了。 Agent 本质上是我们开发者写的一套程序 ,它不是更聪明的 AI,而是一个全程在线的「调度员」,负责在用户、大模型、工具之间协调任务、传递信息、推进流程。
用一个外卖平台来类比这三个角色的关系:

你(用户) :下单的人,提需求
大模型 :后厨主厨,负责决策,先做哪道菜、下一步做什么、什么时候上桌
Agent :外卖平台的调度系统,协调主厨、骑手和顾客,确保整个流程跑通
Tool :骑手和各个执行部门,真正出去跑腿、干具体事情的
大模型只「动脑」,工具才「动手」。Agent 就是把这两者打通的中间层。
具体来说,当你给 Agent 下一条指令:「帮我读取 C 盘目录下的 hello_world.cpp 文件,移动到 D 盘目录下,最后给我总结一下这个文件的核心内容」,整个执行流程是这样的:

Agent 把需求 + 工具清单打包,发给大模型 :「用户想做这件事,你有这些工具可以用,第一步该怎么做?」
大模型做决策,返回指令 :「调用【读取文件】工具,路径是 C://hello_world.cpp」
Agent 执行指令,调用工具 :真正去磁盘上读文件
Agent 把结果回传给大模型 :「文件读取成功,内容是……」
大模型根据结果,决定下一步 :「好,现在调用【移动文件】工具,把它移到 D 盘」
循环执行,直到任务完成 :所有步骤跑完,大模型生成最终总结
- Agent 把结果反馈给你 :任务完成
你看,这整个过程里,「决策」始终在大模型,「执行」始终在工具,而 Agent 就是那个来回传话、推进任务的协调员。
二、Tool 到底是什么?光写函数不够?
好,现在聚焦到工具本身。
你可能会想:「工具不就是函数嘛,我写一个 Python 函数,Agent 直接调用就行了?」
听起来很合理,但这里有个关键问题, 大模型根本看不到你的 Python 代码。
大模型不是程序员,它不会去扫你的代码库,发现「哦你这里有个 get_weather 函数」。它能读的,只有你放进它对话上下文里的文字。
所以,哪怕你把函数写得多优雅,只要没有专门告诉大模型「这个函数叫什么、干嘛用的、参数怎么传」,大模型就永远不知道这个工具的存在。
结论:要让大模型用上工具,必须额外给它写一份「说明书」。
函数是「手」,说明书才是「让大模型学会用这只手的指南」。两者缺一不可。
这份说明书由四个部分组成,就是 Tool 的四要素。
三、Tool 的四要素

函数本体,真正干活的代码
这是实现具体功能的代码,查数据库就是查数据库,发通知就是发通知。
这部分 大模型看不到 ,但是 Agent 最终会执行它。大模型只负责「决策调用哪个工具、传什么参数」,至于这个工具内部怎么实现,大模型完全不关心。
name(名称),大模型的识别标签
大模型决定「调哪个工具」的时候,第一步靠的就是名称。名字要 望名知意 。
get_weather 一眼就知道是「查天气」; func_001 就算加了再多描述,大模型也会更难联想到它的用途。起名的原则很简单:让大模型看名字就能猜出大概。
description(描述),整个工具定义里最重要的字段
没有之一。
大模型每轮决策的核心问题是:「当前这一步,该不该调这个工具?」它做这个判断的 唯一依据 ,就是工具的 description。
描述写清楚了,大模型准确选工具;描述写模糊了,大模型要么选错工具,要么该用的时候没用,或者不该用的时候乱用。
一个好的 description 应该包含三件事:
能做什么 :这个工具的核心功能是什么
什么场景用 :遇到哪类问题、哪种情况该选它
返回什么 :调用完会得到哪些信息
parameters(参数定义),告诉大模型怎么「填参数」
有了函数,大模型还得知道:调用这个工具要传哪些参数、每个参数是什么类型、哪些是必填的。
这些信息用 JSON Schema 格式来定义。
JSON Schema 听起来很技术,但你可以把它理解成 网站上的一张「填写表单」 :
你在网上买东西填收货地址的时候,表单会告诉你,「姓名」「地址」「手机号」是必填项(标了 * 号),「备注」是选填的;「手机号」只能填数字,不能填文字。
JSON Schema 做的就是同样的事:定义这个工具有哪些「格子」需要填、每个格子填什么类型的数据、哪些格子必须填。大模型看到这份定义,就知道该怎么构造调用指令了。
用一个完整的例子把这四个部分串起来。假设我们要给 Agent 提供一个查询天气的工具:
先写函数本体
这段代码没什么特别的,就是调了一个天气 API,把结果整理成字典返回。注意: 大模型看不到这段代码 ,它只负责决定「要调这个工具、传什么参数」,至于你用什么 API、代码怎么写,大模型完全不关心。
再写工具说明书
函数有了,接下来写大模型能看到的部分,name + description + parameters:
来逐行拆解这份说明书:
name字段 :get_weather,望名知意,大模型一看就猜到这是查天气的工具。description字段 :这是最关键的部分。注意它写的不是「这是一个天气 API」,而是写清楚了 使用场景 :「当用户询问某地天气、出行建议、是否需要带伞等问题时使用」。这就是在告诉大模型:你遇到这类问题,就来用我。如果只写「查询天气」,大模型在面对「我明天去杭州要带伞吗」这种问法时,可能就不确定该不该调用了。parameters字段 :定义了两个参数,city(城市名,字符串类型)和date(日期,字符串类型),两个都在required里,也就是「必填格子」,大模型构造调用指令时不会漏填。每个参数的description里还给了例子(「北京、上海、广州」「2025-03-21」),这是个好习惯,大模型按什么格式填参数,全靠这里的说明。
这就是函数本体和工具说明书的完整对照。用户问「明天上海天气怎么样」,大模型读完说明书,就知道:该调 get_weather , city 填「上海」, date 填明天的日期。
四、大模型怎么「认识」这些工具?
工具写好了,下一个问题:大模型怎么知道我有哪些工具?
答案是: 你得主动告诉它。
Agent 在每次对话开始前,会把所有可用工具的 name + description + parameters 打包成一个列表,通过 API 的 tools 参数传给大模型。这个列表就叫 工具清单 。
大模型每次做决策,实际上是在读这份清单,然后判断:「当前任务需要什么操作?哪个工具能完成?该怎么调用?」

用一个场景帮你理解:你入职一家新公司,第一天 HR 给你发了一份《内部系统清单》,
OA 系统 :用来提交请假申请、报销单据。当你需要请假或者报销时使用,填写「开始日期」「结束日期」「事由」。
代码仓库(GitLab) :用来提交代码、发起 MR。当你完成功能开发需要合并代码时使用,填写「分支名」「目标分支」。
监控平台 :用来查看服务状态、报警记录。当排查线上问题时使用,填写「服务名」「时间范围」。
拿到这份清单,你自然就知道:「哦,我下周要请假,得用 OA 系统,填开始日期和结束日期」。
大模型收到工具清单,完全是同样的逻辑,它遇到用户的问题,就在清单里找「哪个工具能处理这个场景」,然后按照 parameters 定义填好参数,告诉 Agent 去调用。
这里有一个结论很重要,要记牢:

大模型选对工具的能力,不只取决于模型有多聪明,更取决于工具描述写得有多清晰。
描述太模糊、两个工具描述太相似、工具太多但没有区分场景,这些问题,换再强的模型也没用。根本原因在工具描述本身写得不够好。这就是为什么前面把 description 列为「最重要的字段」。
工具清单越丰富、描述越清晰,Agent 能干的事越多、越准确。
五、工具有哪些类型?风险从低到高
工具不是只有一种,按照「对系统的影响程度」,从低风险到高风险分成四类。
这个「风险从低到高」的顺序不是随意排的,它决定了每类工具在 Agent 里该怎么用、要不要加人工审批。
查询类(只读)
查天气、搜索网页、读取文件、查数据库记录……只读取数据,不改变任何状态。查完数据库,数据库还是那个数据库;读完文件,文件没有任何变化。
风险等级:低。 这类工具可以放心让 Agent 自主调用,不需要人工确认。出错了顶多是拿到没用的数据,不会产生不可逆的后果。
写入类(有副作用)
往数据库插记录、发通知消息、发邮件、更新配置……会改变系统状态,而且有些操作不可逆,发出去的通知收不回来,写进数据库的记录再删也留了痕迹。
风险等级:中。 对高风险的写入操作(比如发通知给几百个人、修改线上配置),建议加一个人工确认步骤,而不是让 Agent 完全自主执行。
执行类(高风险)
执行 shell 命令、跑脚本、重启服务、部署代码……能直接操作系统。一条错误的 shell 命令能删掉整个目录,一次错误部署能把线上服务打挂。这类工具的影响范围最大,破坏性最强。
风险等级:高。 两件事必须做到:严格限制权限范围(比如只允许执行白名单里的命令);重要操作必须走人工审批,绝对不能让 Agent 自主决策。
AI 辅助类
这是很多同学没想到的一类: AI 能力本身也能封装成工具。
比如,给 Agent 配一个 RAG 检索工具,让它能随时查内部知识库、历史故障案例;或者把一个专门的分类模型封装成工具,Agent 调用它对日志做分类,只拿结论,不需要自己处理所有细节。
风险等级:低到中。 操作本身不会改变外部系统状态,主要关注检索结果的质量和子模型的可靠性。
这四类工具,风险依次递增,设计 Agent 系统时,每个工具的风险等级直接决定了两件事: 它能不能自主调用?需不需要人工确认? 这是保证 Agent 安全可靠运行的基本原则,不要等出了问题再加。
总结
整理一下这章的核心认知:
工具是 Agent 的「双手」 ,没有工具,Agent 只是一个只会输出文字的大模型;有了工具,Agent 才能真正和外部世界交互、完成具体任务。
一个工具 = 函数本体 + 名称 + 描述 + 参数定义 。大模型看不到函数本体,它靠 name + description + parameters 来判断该不该用这个工具、怎么用。其中 description 最关键 ,是大模型选工具的唯一依据。
四类工具,风险从低到高 :
| 类型 | 典型场景 | 风险 | Agent 能自主调用? |
|---|---|---|---|
| 查询类 | 查天气、读文件、搜索网页 | 低 | 可以 |
| 写入类 | 发通知、改配置、写数据库 | 中 | 高风险操作需人工确认 |
| 执行类 | 跑脚本、重启服务、部署代码 | 高 | 必须人工审批 |
| AI 辅助类 | RAG 检索、调用子模型 | 低~中 | 通常可以,关注结果质量 |
工具描述的清晰度决定 Agent 的准确率 ,不是换更聪明的模型,是把 description 写清楚。
后面几章会继续深入这条链路:
Function Calling :大模型是怎么把「我要调哪个工具、传什么参数」这个决策,用标准化格式告诉 Agent 的,这是工具调用的底层机制,这章我们只是看到了结果,下一章讲清楚原理
RAG :把知识库检索封装成工具,让 Agent 能访问私有数据,重要到单独一章
MCP :工具的标准化协议,让你不用每次都从头写工具,直接接入现成的工具生态


